
1. Define the term routing. Differentiate static and dynamic routing.
Routing (or routeing) is the process of selecting paths in a network along which to send network traffic. Routing is performed for many kinds of networks, including the telephone network, electronic data networks (such as the Internet), and transportation networks. In packet switching networks, routing directs packet forwarding, the transit of logically addressed packets from their source toward their ultimate destination through intermediate nodes; typically hardware devices called routers, bridges, gateways, firewalls, or switches
Static Routing
Static routing is not really a protocol, simply the process of manually entering routes into the routing table via a configuration file that is loaded when the routing device starts up. As an alternative, these routes can be enterd by a network administrator who configures the routes. Since these routes don't change after they are configured (unless a human changes them) they are called 'static' routes.
Static routing is the simplest form of routing, but it is a manual process and does not work well when the routing information has to be changed frequently or needs to be configured on a large number of routing devices (routers). Static routing also does not handle outages or down connections well because any route that is configured manually must be reconfigured manually to fix or repair any lost connectivity.
Dynamic Routing
Dynamic routing protocols are software applications that dynamically discover network destinations and how to get to them.
A router will 'learn' routes to all directly connected networks first. It will then learn routes from other routers that run the same routing protocol. The router will then sort through it's list of routes and select one or more 'best' routes for each network destination it knows or has learned.
Dynamic protocols will then distribute this 'best route' information to other routers running the same routing protocol, thereby extending the information on what networks exist and can be reached. This gives dynamic routing protocols the ability to adapt to logical network topology changes, equipment failures or network outages 'on the fly'.
2. Differentiate IPv4 and IPv6 addressing schemes.
Pv6 is based on IPv4, it is an evolution of IPv4. So many things that we find with IPv6 are familiar to us. The main differences are:
1.Simplified header format. IPv6 has a fixed length header, which does not include most of the options an IPv4 header can include. Even though the IPv6 header contains two 128 bit addresses (source and destination IP address) the whole header has a fixed length of 40 bytes only. This allows for faster processing.
Options are dealt with in extension headers, which are only inserted after the IPv6 header if needed. So for instance if a packet needs to be fragmented, the fragmentation header is inserted after the IPv6 header. The basic set of extension headers is defined in RFC 2460.
2.Address extended to 128 bits. This allows for hierarchical structure of the address space and provides enough addresses for almost every 'grain of sand' on the earth. Important for security and new services/devices that will need multiple IP addresses and/or permanent connectivity.
3.A lot of the new IPv6 functionality is built into ICMPv6 such as Neighbor Discovery, Autoconfiguration, Multicast Listener Discovery, Path MTU Discovery.
4.Enhanced Security and QoS Features.
IPv4 means Internet Protocol version 4, whereas IPv6 means Internet Protocol version 6. IPv4 is 32 bits IP address that we use commonly, it can be 192.168.8.1, 10.3.4.5 or other 32 bits IP addresses. IPv4 can support up to 232 addresses, however the 32 bits IPv4 addresses are finishing to be used in near future, so IPv6 is developed as a replacement. IPv6 is 128 bits, can support up to 2128 addresses to fulfill future needs with better security and network related features. Here are some examples of IPv6 address: 1050:0:0:0:5:600:300c:326b
ff06::c3
0:0:0:0:0:0:192.1.56.10
3. Describe the following:
a. Congestion
Network congestion occurs when a queue buffer of a network node is full and starts to drop packets. Automatic repeat request may keep the network in a congested state. This situation can be avoided by adding congestion avoidance to the flow control, including slow-start. This keeps the bandwidth consumption at a low level in the beginning of the transmission, or after packet retransmission.
b. Congestion Control
One of the main principles for congestion control is avoidance. TCP tries to detect signs of congestion before it happens and to reduce or increase the load into the network accordingly. The alternative of waiting for congestion and then reacting is much worse because once a network saturates, it does so at an exponential growth rate and reduces overall throughput enormously. It takes a long time for the queues to drain, and then all senders again repeat this cycle. By taking a proactive congestion avoidance approach, the pipe is kept as full as possible without the danger of network saturation. The key is for the sender to understand the state of the network and client and to control the amount of traffic injected into the system. Flow control is accomplished by the receiver sending back a window to the sender. The size of this window, called the receive window, tells the sender how much data to send. Often, when the client is saturated, it might not be able to send back a receive window to the sender to signal it to slow down transmission. However, the sliding windows protocol is designed to let the sender know, before reaching a meltdown, to start slowing down transmission by a steadily decreasing window size. At the same time these flow control windows are going back and forth, the speed at which ACKs come back from the receiver to the sender provides additional information to the sender that caps the amount of data to send to the client. This is computed indirectly.
4. Discuss the Remote Procedure Calls and their importance in Session Layer.
Remote Procedure Call (RPC) is a protocol which works in session layer of OSI model and in the Application Layer of TCP/IP model. It is useful in developing network applications which need services from a remote computer in the network. With the help of Remote Procedure Call the programmer need not worry about the complex structure of OSI layer.
Working of Remote Procedure Call
1. RPC is working as a client server model
2. RPC uses different Authentication methods to validate the client request.
3. RPC protocol is independent of transport layer protocols.
4. RPC reuests can use both UDP and TCP but prefer UDP format
RPC uses the client/server model. The requesting program is a client and the service-providing program is the server. First, the caller process sends a call message that includes the procedure parameters to the server process. Then, the caller process waits for a reply message (blocks). Next, a process on the server side, which is dormant until the arrival of the call message, extracts the procedure parameters, computes the results, and sends a reply message. The server waits for the next call message. Finally, a process on the caller receives the reply message, extracts the results of the procedure, and the caller resumes execution.
5. Discuss Simple Mail Transfer Protocol in detail.
Simple Mail Transfer Protocol (SMTP), documented in RFC 821, is Internet's standard host-to-host mail transport protocol and traditionally operates over TCP, port 25. In other words, a UNIX user can type telnet hostname 25 and connect with an SMTP server, if one is present. SMTP uses a style of asymmetric request-response protocol popular in the early 1980s, and still seen occasionally, most often in mail protocols. The protocol is designed to be equally useful to either a computer or a human, though not too forgiving of the human. From the server's viewpoint, a clear set of commands is provided and well-documented in the RFC. For the human, all the commands are clearly terminated by newlines and a HELP command lists all of them. From the sender's viewpoint, the command replies always take the form of text lines, each starting with a three-digit code identifying the result of the operation, a continuation character to indicate another lines following, and then arbitrary text information designed to be informative to a human.
If mail delivery fails, sendmail (the most important SMTP implementation) will queue mail messages and retry delivery later. However, a backoff algorithm is used, and no mechanism exists to poll all Internet hosts for mail, nor does SMTP provide any mailbox facility, or any special features beyond mail transport. For these reasons, SMTP isn't a good choice for hosts situated behind highly unpredictable lines (like modems). A better-connected host can be designated as a DNS mail exchanger, then arrange for a relay scheme. Currently, there two main configurations that can be used. One is to configure POP mailboxes and a POP server on the exchange host, and let all users use POP-enabled mail clients. The other possibility is to arrange for a periodic SMTP mail transfer from the exchange host to another, local SMTP exchange host which has been queuing all the outbound mail. Of course, since this solution does not allow full-time Internet access, it is not too preferred. RFC 1869 defined the capability for SMTP service extensions, creating Extended SMTP, or ESMTP. ESMTP is by definition extensible, allowing new service extensions to be defined and registered with IANA. Probably the most important extension currently available is Delivery Status Notification (DSN), defined in RFC 1891.
6. Explain any two static routing algorithms.
Dijkstra's algorithm, conceived by Dutch computer scientist Edsger Dijkstra in 1959,[1] is a graph search algorithm that solves the single-source shortest path problem for a graph with nonnegative edge path costs, producing a shortest path tree. This algorithm is often used in routing. An equivalent algorithm was developed by Edward F. Moore in 1957. Let the node at which we are starting be called the initial node. Let the distance of node Y be the distance from the initial node to Y. Dijkstra's algorithm will assign some initial distance values and will try to improve them step-by-step.
Assign to every node a distance value. Set it to zero for our initial node and to infinity for all other nodes.
Mark all nodes as unvisited. Set initial node as current.
For current node, consider all its unvisited neighbors and calculate their distance (from the initial node). For example, if current node (A) has distance of 6, and an edge connecting it with another node (B) is 2, the distance to B through A will be 6+2=8. If this distance is less than the previously recorded distance (infinity in the beginning, zero for the initial node), overwrite the distance.
When we are done considering all neighbors of the current node, mark it as visited. A visited node will not be checked ever again; its distance recorded now is final and minimal.
If all nodes have been visited, finish. Otherwise, set the unvisited node with the smallest distance (from the initial node) as the next "current node" and continue from step 3.
Suppose you want to find the shortest path between two intersections on a map, a starting point and a destination. To accomplish this, you could highlight the streets (tracing the streets with a marker) in a certain order, until you have a route highlighted from the starting point to the destination. The order is conceptually simple: at each iteration, create a set of intersections consisting of every unmarked intersection that is directly connected to a marked intersection, this will be your set of considered intersections. From that set of considered intersections, find the closest intersection to the destination (this is the "greedy" part, as described above) and highlight it and mark that street to that intersection, draw an arrow with the direction, then repeat. In each stage mark just one new intersection. When you get to the destination, follow the arrows backwards. There will be only one path back against the arrows, the shortest one.
A flooding algorithm is an algorithm for distributing material to every part of a connected network. The name derives from the concept of inundation by a flood.Flooding algorithms are used in systems such as Usenet and peer-to-peer file sharing systems and as part of some routing protocols, including OSPF, DVMRP, and those used in ad-hoc wireless networks.There are several variants of flooding algorithm: most work roughly as follows.
Each node acts as both a transmitter and a receiver.
Each node tries to forward every message to every one of its neighbors except the source node.
This results in every message eventually being delivered to all reachable parts of the network Real-world flooding algorithms have to be more complex than this, since precautions have to be taken to avoid wasted duplicate deliveries and infinite loops, and to allow messages to eventually expire from the system. Flooding algorithms are also useful for solving many mathematical problems, including maze problems and many problems in graph theory.
7. Discuss IPv4 addressing schemes.
Internet Protocol version 4 (IPv4) is the fourth revision in the development of the Internet Protocol (IP) and it is the first version of the protocol to be widely deployed. Together with IPv6, it is at the core of standards-based internetworking methods of the Internet. IPv4 is still by far the most widely deployed Internet Layer protocol. As of 2010, IPv6 deployment is still in its infancy. IPv4 uses 32-bit (four-byte) addresses, which limits the address space to 4,294,967,296 (232) possible unique addresses. However, some are reserved for special purposes such as private networks (~18 million addresses) or multicast addresses (~270 million addresses). This reduces the number of addresses that can potentially be allocated for routing on the public Internet. As addresses are being incrementally delegated to end users, an IPv4 address shortage has been developing, however network addressing architecture redesign via classful network design, Classless Inter-Domain Routing, and network address translation (NAT) has significantly delayed the inevitable exhaustion.This limitation has stimulated the development of IPv6, which is currently in the early stages of deployment, and is the only long-term solution.Pv4 addresses are usually written in dot-decimal notation, which consists of the four octets of the address expressed in decimal and separated by periods. This is the base format used in the conversion in the following table:
Notation
Value
Conversion from dot-decimal
Dot-decimal notation
192.0.2.235
N/A
Dotted Hexadecimal
0xC0.0x00.0x02.0xEB
Each octet is individually converted to hexadecimal form
Dotted Octal
0300.0000.0002.0353
Each octet is individually converted into octal
Hexadecimal
0xC00002EB
Concatenation of the octets from the dotted hexadecimal
Decimal
3221226219
The 32-bit number expressed in decimal
Octal
030000001353
The 32-bit number expressed in octal
Most of these formats should work in all browsers. Additionally, in dotted format, each octet can be of any of the different bases. For example, 192.0x00.0002.235 is a valid (though unconventional) equivalent to the above addresses.A final form is not really a notation since it is rarely written in an ASCII string notation. That form is a binary form of the hexadecimal notation in binary. This difference is merely the representational difference between the string "0xCF8E83EB" and the 32-bit integer value 0xCF8E83EB. This form is used for assigning the source and destination fields in a software program.
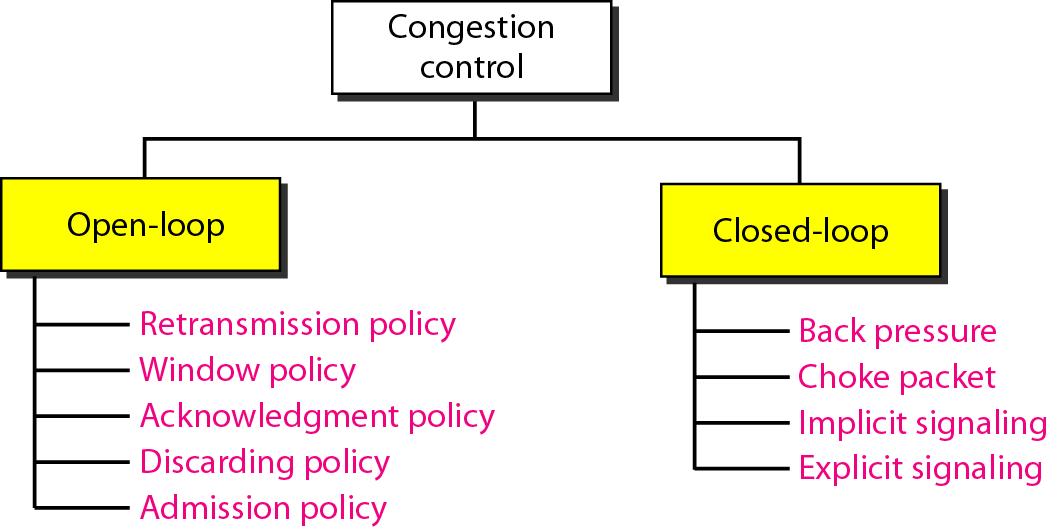
8. Discuss Congestion Avoidance in Transport Layer.
Open loop solutions solve the problem by good design, in essence, to make sure the problem does not occur in the first place.
Tools include deciding when to accept new traffic, when to discard packets and which ones, and how to schedule packets at various points in the network. A common fact: they make decisions without regard to the current state of the network.
Closed loop solutions are based on the concept of a feedback loop, which consists of the following three parts:
Monitor the system to detect when and where congestion occurs.
Pass this information to places where actions can be taken.
Adjust system operation to correct the problem.
9. Discuss various design issues of Session Layer.
The session layer allows users on different machines to establish sessions between them. A session allows ordinary data transport, as does the transport layer, but it also provides enhanced services useful in some applications.
Some of these services are:
Dialog control - session can allow traffic to go in both directions at the same time, or in only one direction at a time. If traffic can go only in one way at a time, the session layer can help to keep track of whose turn it is. Simplex Dialogs - One way transfers, similar to an old computer/printer. Data could be sent to the printer but the printer could not communicate back.
Half-Duplex Dialogs - Two-way transfers. Each device must take their turn. Both cannot transfer at the same time.
Full-Duplex Dialogs - Two-way simultaneous data transfers. Each device has it's own channel. Telephones are full duplex, as are most modems. Full duplex is the most expensive to implement.
Token management - for some protocols it is essential that both sides do not attempt the same operation at the same time. The session layer provides tokens that can be exchanged. Only the side holding the token may perform the critical action.
Synchronization - by inserting checkpoints into the data stream the layer eliminates problems with potential crashes at long operations. After a crash, only the data transferred after the last checkpoint have to be repeated.
The user of the session layer is in similar position as the user of the transport layer but having larger possibilities. Session Administration: A session is a dialog or conversation between a service requester and a service provider. There are three phases:
Connection Establishment
Several tasks can be done at this phase:
Specification of required services
Login authentication and other security procedures
Protocol negotiation and parameters
Notification of connection IDs
Establishment of dialog control, as well as acknowledgment of numbering, and retransmission procedures.
Data Transfer
Once the connection has been established, the devices exchange data, acknowledgments, and other control data that manage the dialog. The session layer can also incorporate protocols to resume broken dialogs. If a connection has not been properly released, the session can be resumed without re-establishment. The devices have a specified time period to do so.
Connection Release
Consists of shutting down communications and releasing resources on the service provider in an orderly fashion.
10. Describe the Multipurpose Internet Mail Extensions.
Multipurpose Internet Mail Extensions (MIME) is an Internet standard that extends the format of e-mail to support:
Text in character sets other than ASCII
Non-text attachments
Message bodies with multiple parts
Header information in non-ASCII character sets
MIME's use, however, has grown beyond describing the content of e-mail to describing content type in general, including for the web (see Internet media type).Virtually all human-written Internet e-mail and a fairly large proportion of automated e-mail is transmitted via SMTP in MIME format. Internet e-mail is so closely associated with the SMTP and MIME standards that it is sometimes called SMTP/MIME e-mail.The content types defined by MIME standards are also of importance outside of e-mail, such as in communication protocols like HTTP for the World Wide Web. HTTP requires that data be transmitted in the context of e-mail-like messages, although the data most often is not actually e-mail. The basic Internet e-mail transmission protocol, SMTP, supports only 7-bit ASCII characters (see also 8BITMIME). This effectively limits Internet e-mail to messages which, when transmitted, include only the characters sufficient for writing a small number of languages, primarily English. Other languages based on the Latin alphabet typically include diacritics not supported in 7-bit ASCII, meaning text in these languages cannot be correctly represented in basic e-mail. MIME defines mechanisms for sending other kinds of information in e-mail. These include text in languages other than English using character encodings other than ASCII, and 8-bit binary content such as files containing images, sounds, movies, and computer programs. MIME is also a fundamental component of communication protocols such as HTTP, which requires that data be transmitted in the context of e-mail-like messages even though the data might not (and usually doesn't) actually have anything to do with e-mail. Mapping messages into and out of MIME format is typically done automatically by an e-mail client or by mail servers when sending or receiving Internet (SMTP/MIME) e-mail.


{kind=link}
Post a Comment
Post a Comment